

A peek into the world of data engineering #1
A peek into the world of data engineering #1

Why this blog series
I like researching about Data and how companies are evolving their architectures and advancing in today’s era in the world of data. A lot of my friends and colleagues ask me to share my what I have been reading or working on; I thought it might be a worthwhile experiment to start writing my findings and summarizing `what’s brewing in the data space`, share aggregated views on data frameworks etc on a regular cadence. While I adjust the frequency of this blog series( which I think should be fortnightly) to find the right fit, I would highly appreciate your feedback on how I can make this worth your time(write to me at neoeahit@gmail.com if you have any feedback). Now onto more happening data updates.
Visualization of the week
In this section I try to share one visualization or data analysis which I liked over last week, or which blew my mind!
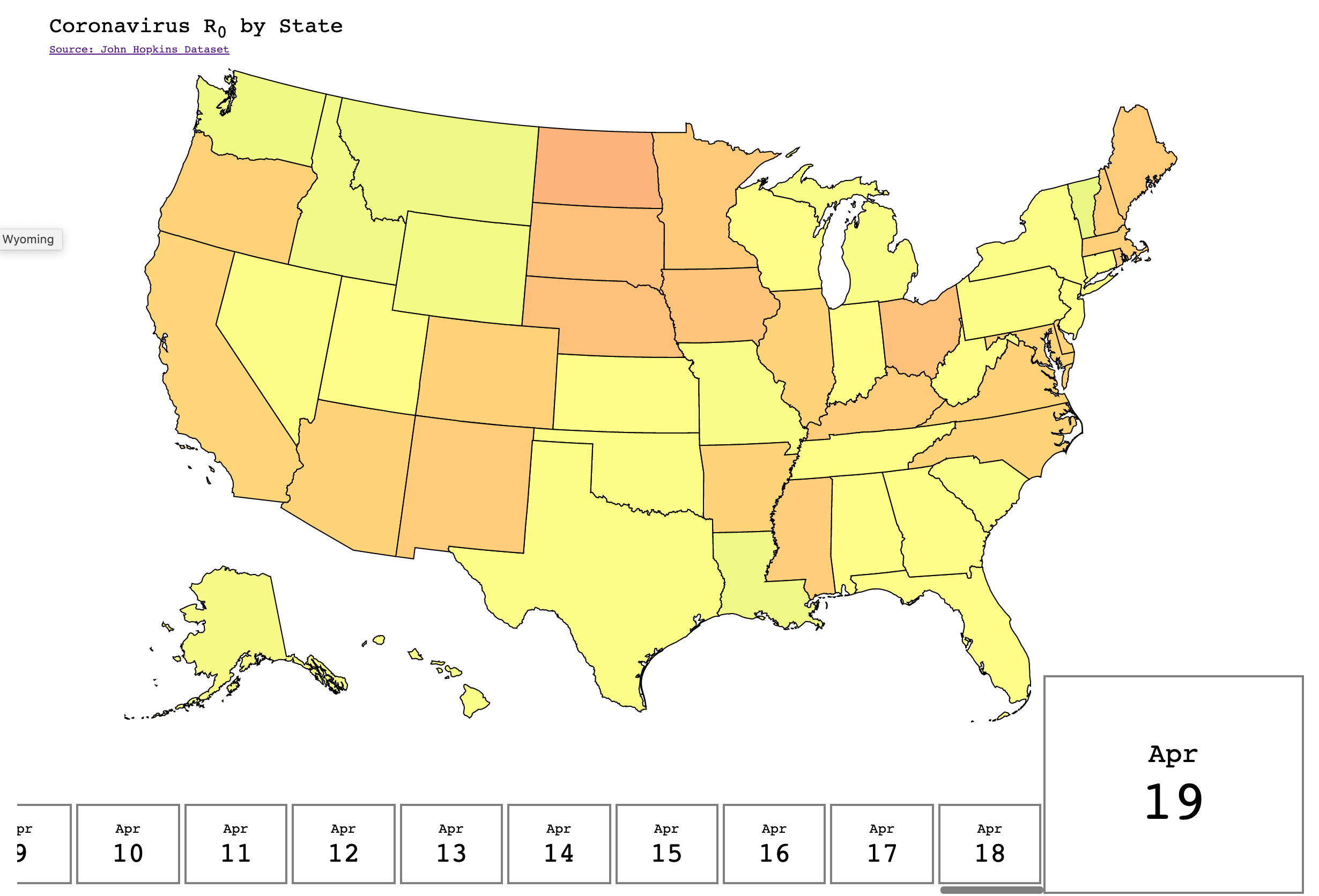
(Remember to scroll right/left to see the visualization)
Source: https://flattenthevir.us/, Shoutout to Dan, for creating this amazing visualization.
Blog Updates
Spotify releases Podcast Dataset and TREC Challengeto enable research and understanding of Podcast content - focusing primarily on ‘search’ and ‘summarization’. With the 100,000 episodes released with transcription, the aim is to understand content - to answer not only which podcasts to listen to, but also to draw insights and learnings to identify and jump to specific parts of a podcast.
More Details:http://podcastsdataset.byspotify.com/
LinkedIn talks about its advanced schema management for spark applications; the blog delves into schema evolution and how the infrastructure provides managed schema classes to developers and delves into Dali(their hive metastore).
More Details: https://engineering.linkedin.com/blog/2020/advanced-schema-management-for-spark
Google recently shared details on how to connect and sync data between MySQL and BigQuery utilizing Dataflow and Debezium
More Details:https://github.com/GoogleCloudPlatform/DataflowTemplates/tree/master/v2/cdc-parent
Apache Kafka 2.5.0 was released; some highlights of this release include
Improvements to multiple partition production and reliability while using transactional producer
Preparatory work to remove dependency on Zookeeper for broker election and metadata management
Dropped support for Scala 2.11
Materialized views support for stream of events
More Details: https://www.confluent.io/blog/apache-kafka-2-5-latest-version-updates/
Apache Flink - Stateful functions 2.0
Think of an event driven database - where users can implement functions that receive and send messages. Flink can now invoke functions via HTTP or gRPC based on incoming events and allow state access. Now imagine this integrated with K8s - we have function containers communicating with each other via the pod-network.
More Details: https://flink.apache.org/news/2020/04/07/release-statefun-2.0.0.html
Upcoming Talks and Conferences:
Due to covid-19 situation, a lot of conferences have been cancelled, rescheduled to later, or being held virtually now. Below are a list of conferences relating to data which are being held virtual:
Flink Forward, April 22nd - 24th
Spark and AI summit, June 24th - June 25
That’s all for this week. Your feedback is welcome!
Note: This blog series is for informational purposes only, and all views are my own and do not represent my employers.