
A peek into the world of data strategy #3
This week's series contains recent blog posts from Uber, LinkedIn, Tableau and Amazon. The focus of this week is on ways to improve trust on your data and improve analytics.

Who is this current post for:
Product Managers and Engineers passionate about data quality and improved analytics
Hope everyone is safe and fine during these coronavirus times!
As you remember I usually start any of my blogs with a good visualization which I have come across during the week; this week I would like to highlight this one from New York Times for Coronavirus in the U.S.: Latest Map and Case Count
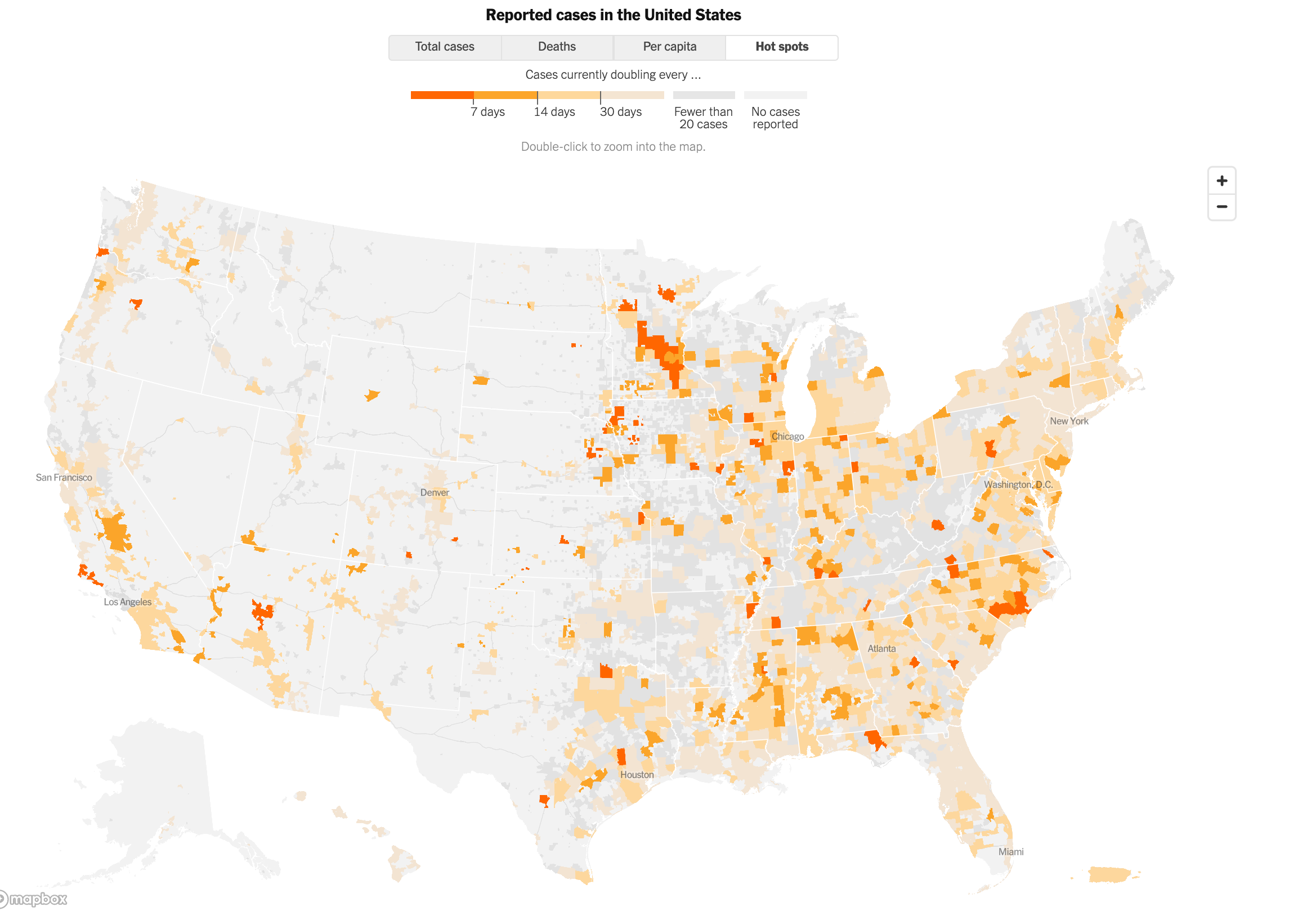
Check it out, it provides a visual report of current status of coronavirus cases in USA.
Do you want to get more of these blog updates, subscribe to the newsletter using the link below
Now onto the blog…
Uber published its blog on monitoring Data Quality at Scale. In the blog Uber explains how they leverage a solution using statistical modelling(using PCA, Holt-Winters model, etc) to analyse historical patterns to discover anomalies and then alerts affected consumers. Helping reduce the mean time to detection of data issues helps in improving trust on their data thereby allowing for accurate decision making.
Article: https://eng.uber.com/monitoring-data-quality-at-scale/
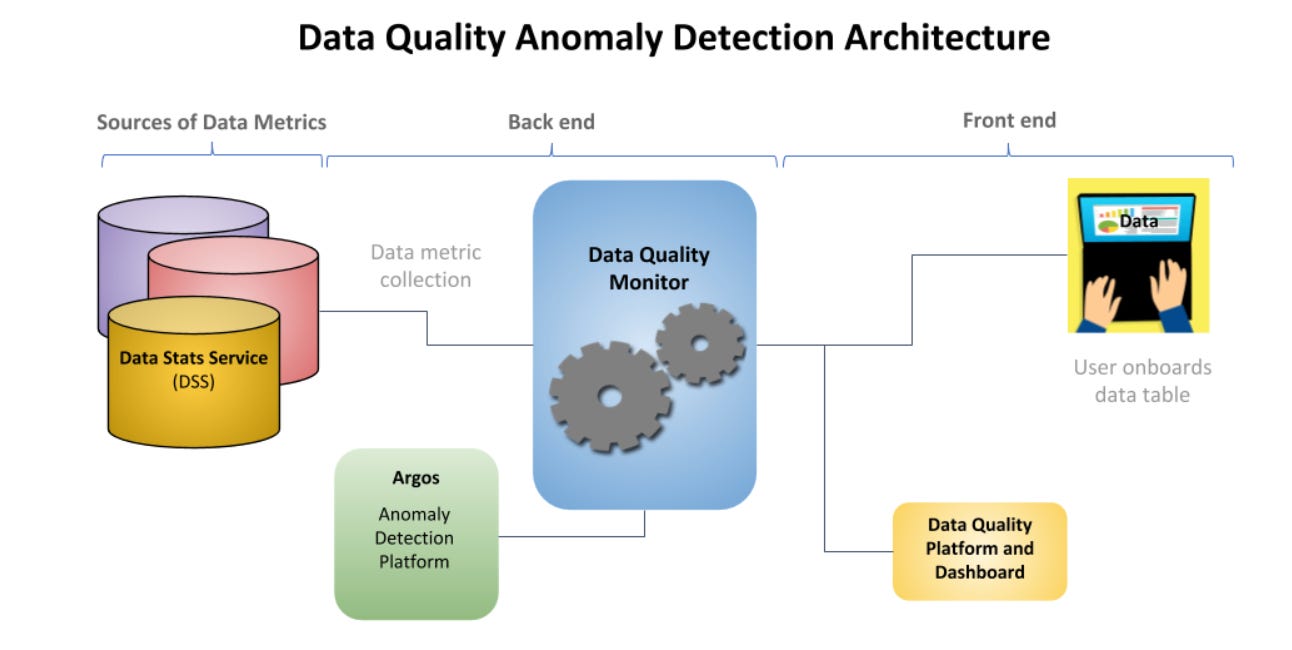
The next blog looks at terms like data quality and data cleansing and how to build a data quality(DQ) framework that works for your data needs. The article classifies DQ metrics into following three levels and suggests how to optimize data cleaning efforts to help build better trust on your data.
Level 1: Generic DQ metrics
Level 2: Contextual checks like data ranges and column relationships
Level 3: Comparative checks
Linkedin writes about its 0.3.0 update of Apache Pinot - a scalable OLAP data store that they use to power analytics (use-cases include: Who Viewed My Profile, UberEats Restaurant Manager, Talent Analytics and others). The new version includes support for:
Plug-in architecture for various data sources/stores
Full SQL support on Pinot
Deep storage support for Google Cloud Storage, Azure data lake storage and S3
Enabling cloud-based deployment for K8s
Article: https://engineering.linkedin.com/blog/2020/apache-pinot-030-update
DataCraft published an article on how to use open source technologies to draw real-time insights for your supply chain. Using technologies like Apache NiFi, Apache Flink and Apache Zeppelin one can create event-driven alerting system thereby helping and empowering store managers to take charge of their inventories.
Article: https://towardsdatascience.com/event-driven-supply-chain-for-crisis-with-flinksql-be80cb3ad4f9
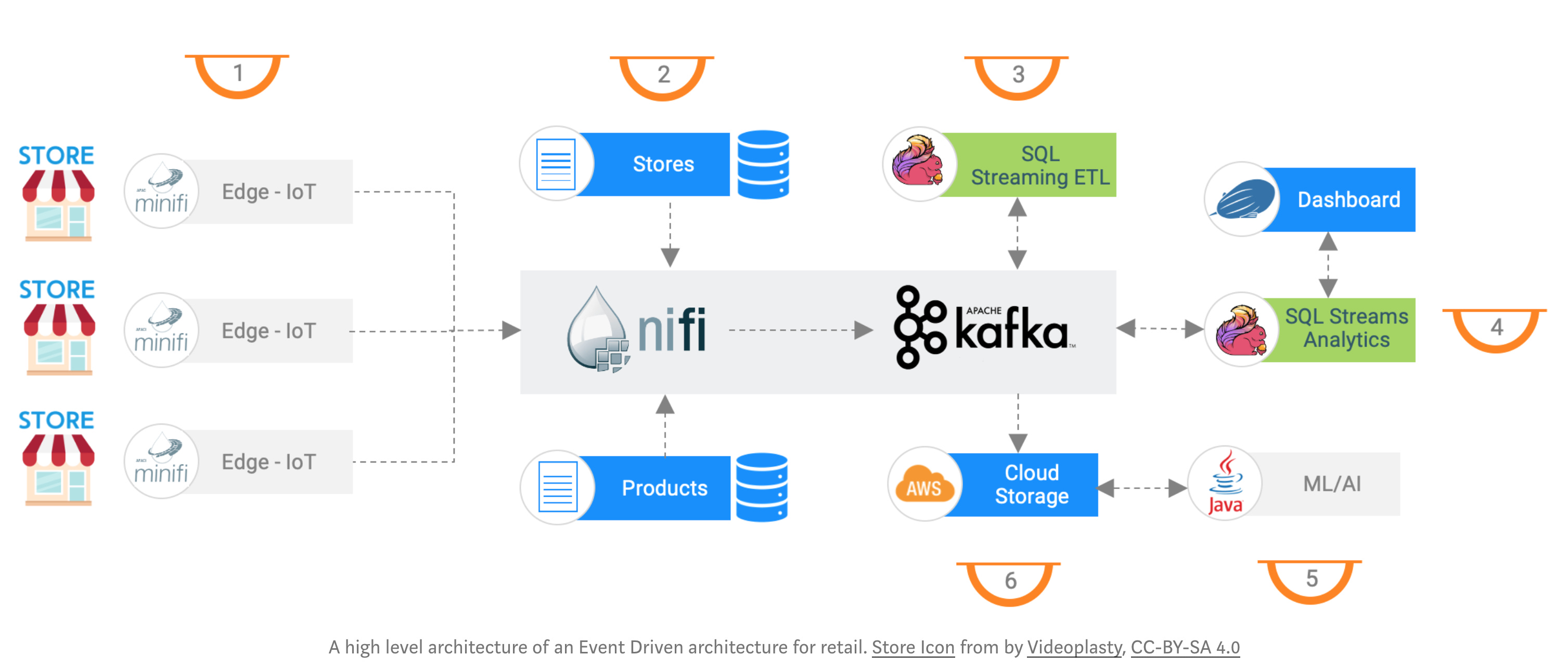
Tableau releases version 2020.2 with exciting features for:
Incremental refresh to detect new rows and update and process only the new rows thereby allowing you to save time and resources
Salesforce connector for Tableau Prep
High visibility quality warnings thereby empowering your customers to decide whether or not to use the viz for critical decision-making
Amazon releases UltraWarm at General Availability. UltraWarm is aws’s new low-cost storage providing interactive analytics on up to three petabytes of log data, at one-tenth cost of the current Amazon Elasticsearch Service storage tier. So $$$ savings! If you are planning on building a search system for your website, or want an efficient solution for storing, or need to analyze data from application or infrastructure logs - Elasticsearch might help answer your problems.
Article: https://aws.amazon.com/blogs/aws/general-availability-of-ultrawarm-for-amazon-elasticsearch-service/
Upcoming Conferences:
Date: May 12th-13th
RedisConf Takeaway is a free, virtual learning conference where you can explore the latest innovations and trends in data platforms, share your ideas, learn from other Redis experts across the globe, and develop your Redis skills with hands-on training – all from your home office. At RedisConf 2020, we invite you to Rediscover what you can do with Redis – with a live keynote, 50+ breakout sessions, hackathon, 1:1 office hours with Redis experts, group chats, games, and more. Join us, free of charge, from May 12-13.
Date: May 12th
Hear from open source and industry thought leaders about the latest trends in big data, analytics and AI. Get an in-depth look at open-source technologies like Apache Spark™, Delta Lake, MLflow, Koalas, TensorFlow and PyTorch.
Date: May 14th-15th
The Data Science Conference is a uniquely excellent conference. The organizers curate a great mix of topics. Whether it's talks about Attention and Reinforcement from the bleeding edge AI, novel applications of Machine Learning to AgTech, or the musings of industry leaders on the future of data science education I'm sure I'll be hearing something interesting. Moreover, the informed and passionate attendees not trying to sell you anything guarantees a fun networking session!
That’s all for this week. Your feedback is welcome!
Note: This blog series is for informational purposes only, and all views are my own and do not represent my employers.