
A peek into the world of data strategy #6
This week's post includes articles from Uber, Rancher Labs, Flink and Stream Thoughts.

Who is this current post for:
Product Managers and Engineers passionate about building insights using data and scaling their analytics pipelines.
Love this blog? signup to receive weekly updates:
Uber writes about Hudi, their transactional data lake solution which facilitates quick, reliable data updates at scale.
Article: https://eng.uber.com/apache-hudi-graduation/

Another post from Uber! Uber open-sources neuropod, an abstraction layer on top of existing deep learning frameworks that provides a uniform interface to run any deep learning models. Neuropod empowers researchers to build models in a framework of their choosing and also provides ways to productionize them.
Article: https://eng.uber.com/introducing-neuropod/
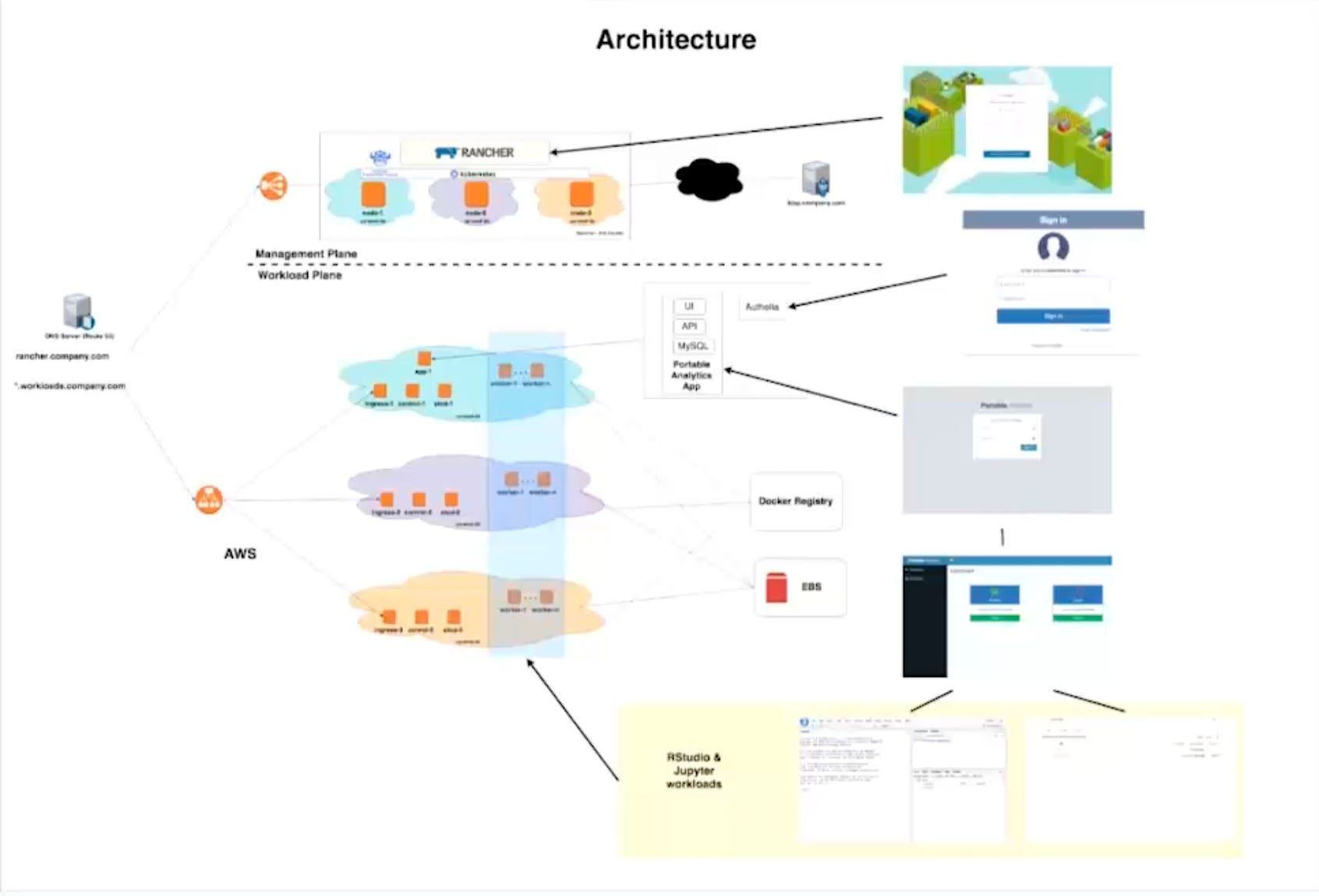
Murali Paluru from Rancher Labs shares their experiences on how to leverage Kubernetes to build a scalable data science and machine learning cloud, and some of the common mistakes and pitfalls which should be avoided. With a focus on building RStudio and Jupyter workloads, Murali talks about the challenges on authentication, high availability etc.
Article: https://www.infoq.com/presentations/leveraging-kubernetes-arch
Flink releases Stateful Functions 2.1! This release introduces two new features: state expiration for any kind of persisted state and support for UNIX Domain Sockets (UDS) to improve the performance of inter-container communication in co-located deployments
Article: https://flink.apache.org/news/2020/06/09/release-statefun-2.1.0.html
Florian Hussonnois from StreamThoughts writes about building a real-time analytical pipeline using kafka, ksqldb, clickhouse and superset. Pretty interesting read on how to leverage open-source technologies to build your analytical pipelines!
That’s all for this week. Your feedback is welcome!
Note: This blog series is for informational purposes only, and all views are my own and do not represent my employers.