
In-house Data Discovery platforms #2

My focus this week is on showcasing different in-house data discovery platforms out there, and comparing their functionality. Fair warning this post is going to be a slightly long one - I have tried to summarize my key findings at the beginning of this article to make this an easy read.
Please note most insights in this article are compiled to the best of my knowledge after researching various engineering blogs and articles, so incase you feel something is incorrect, please contact me at neoeahit@gmail.com, and i will update this article asap.
Also always open to feedback on how to make this blog series better, so please do sign up and leave comments on what more you want to see next
Quick Summary
This article is focussed on showcasing the featureset, technical stack, supported datastores and industry trends of the various data discovery platforms at Spotify, Airbnb, Lyft, Uber, Netflix and LinkedIn.
Who should read this?
Anyone who is interested in data and faces the everyday problems on finding the `right` data. Investing in the right data discovery platform improves overall productivity by x folds!
Now onto this week’s update.
In today’s world producing data is cheap. The projection is that the amount of digital data generated will grow from 33 ZB in 2018 to 175 ZB by 2025 as shown in the figure below.
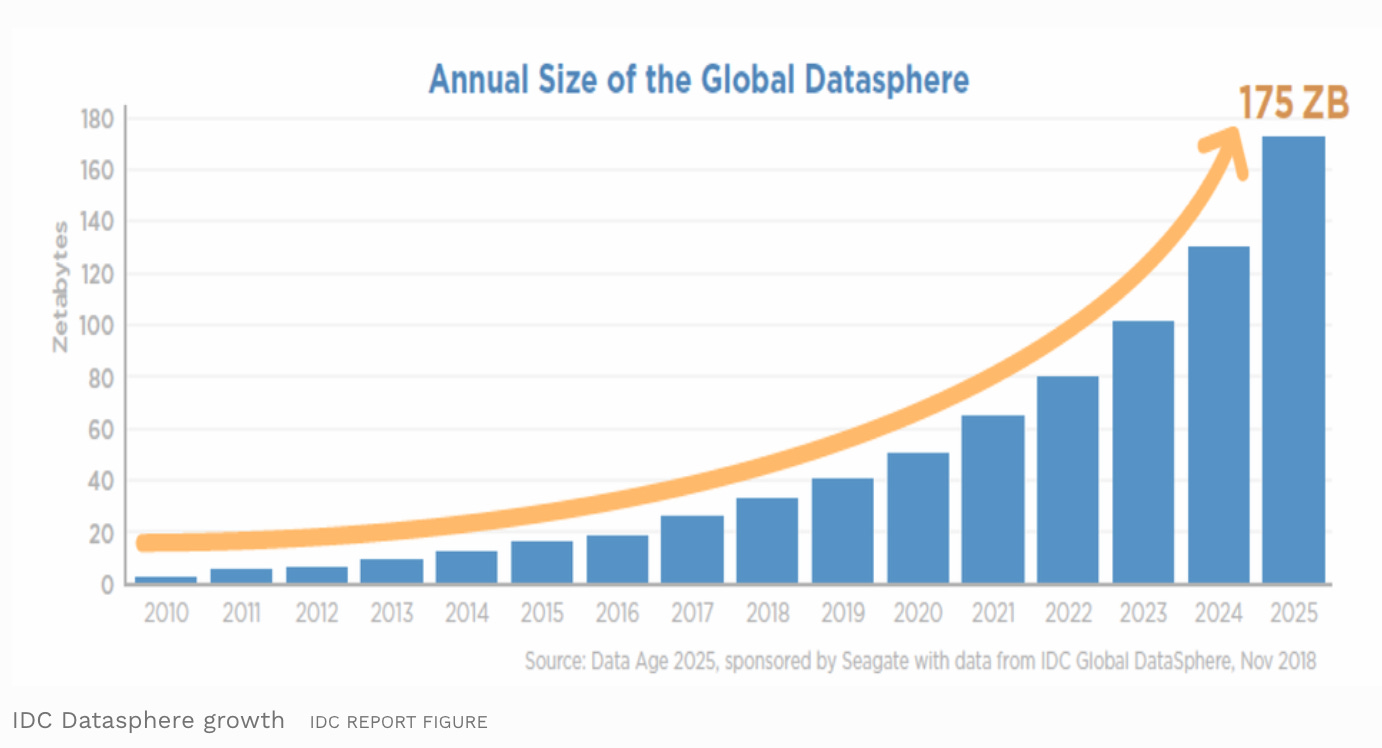
This growth of data has presented new challenges to organizations - today a significant amount of time is spend in discovering the `correct` data. Quoting from Lyft’s blog
At Lyft, what we observed was that the while we wanted the majority of the time to be spent in model development (aka prototyping) and productionalization, a lot of the time was being spent in data discovery.

Data discovery has become such an important problem that companies are investing in data inventory and insights platforms. As you would have guessed this article is all about this :)
But before we start looking at the platforms out there, let’s actually try to understand the common questions which people want answers to which has actually lead to these solutions being built. A product ideally cannot exist without a need.
Where do I find the data I am looking for?
I have questions on this data, who should I reach out to?
Should I blindly trust this data?
How do people commonly interact with this data?
The present research is based on 6 data discovery platforms built at Airbnb, Spotify, Uber, Netflix, LinkedIn and Lyft. While the tech stack may vary, all these platforms aim at solving the most important problem of cataloging and managing data inventory.
A quick summary of the capabilities of these platforms is provided below:

Metadata, Stewardship and Data profiling are the common functionalities provided by almost all these platforms. To be honest and based on my experience also these are the core of the problems of the data inventory space.
Next onto the tech stack:

Depending on whether you are building a solution based on crawling your data inventory, or a push based approach where you want to update your catalog whenever a new data-asset is created, or you are trying a combination of push-pull - the tech stack varies on these different platforms - but unique thing common to all is how scalability is one of the common factors driving their architecting - data will just continue to grow and we need to ensure our platforms can scale.
Supported datastores/products

What’s next?
This section is highly speculative, and is based on above roadmap’s and release notes.
It seems like the general trend is to provide native lineage capabilities to show how data assets interact with each other, provide more granular access controls, more personalization features and suggestions to discover trends amongst various data-assets.
Now let’s look at each of the platforms…
Amundsen - Lyft
Official Blog: https://eng.lyft.com/open-sourcing-amundsen-a-data-discovery-and-metadata-platform-2282bb436234

Amundsen is Lyft’s data discovery platform. It consists of a databuilder aka data crawler which crawls the all dashboards, databases and HR systems to pull in any newly created datasets and any changes to inventory; the search is based off an elasticsearch solution basing search results off relevancy, category and fuzzy wildcard searching. Amundsen provides insights on columnar entities such as count, count_null, count_distinct, len_max, len_min, len_avg, len_sum

(Source: Data Council SF Amundsen Presentation)
Conference Talk:
DataHub - LinkedIn
Official Blog: https://engineering.linkedin.com/blog/2019/data-hub

An evolution to WherseHows, datahub is built on the vision to connect Linkedin employees with data which matters most to them. Datahub’s focus is not only on metadata records, but collects and indexes metrics, jobs, charts, people and groups, and provides a one stop shop discovery and lineage portal at LinkedIn.
One of the important aspects of building an aggregation and search tool is the ability to quickly find your answers - datahub allows for advanced searching utilizing OR, AND and regexes, and allowing slicing and dicing and filtering using facets thereby allowing its users to find the data quickly.
Metadata ingestion is primarily push based and is achieved using either APIs or Kafka streams. Utilizing a kafka stream approach allows metadata producers to send a Metadata Change Event (MCE) thereby allowing a scalable architecture. All metadata stored in Datahub is modelled using Pegasus data schema language.
Datahub has been released on github; as mentioned on blog there are differences between their internal and external version - I will not mention those here, as those are available on their blog.

Open source DataHub architecture ( source )
Conference Talk:
Dataportal - Airbnb
Official Blog: https://medium.com/airbnb-engineering/democratizing-data-at-airbnb-852d76c51770
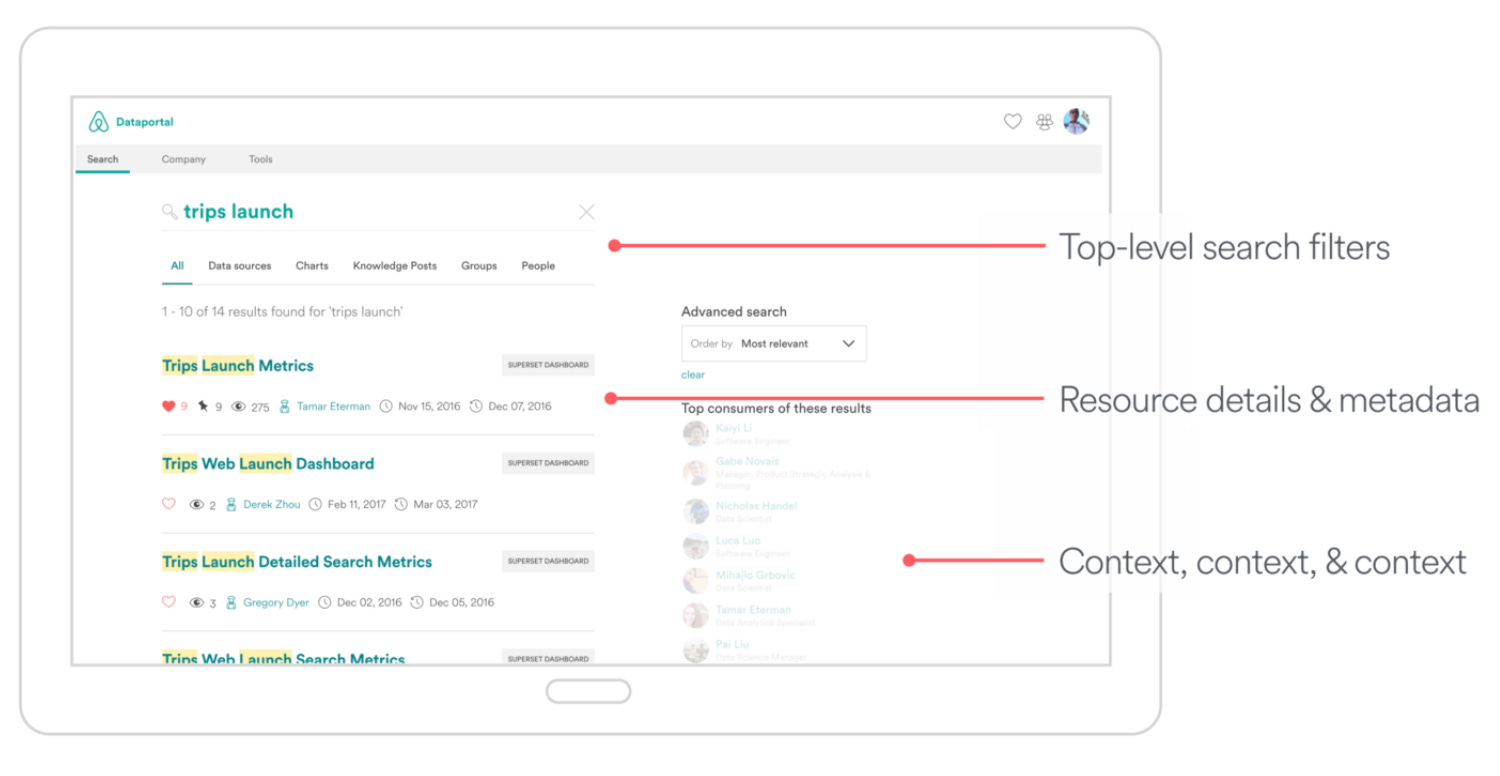
Airbnb built their data discovery platform to aide its employees with data exploration, discovery, and trust. Users can search for a plethora of inventory ranging from logging schemas, data tables, charts, dashboards, employees, and teams. An inventory result provides insights also into consumers, data stewards and creation and update date, highlighting column popularity and the distribution of column values for low-cardinality columns .
Conference Talk:
Lexikon - Spotify
Official Blog: https://labs.spotify.com/2020/02/27/how-we-improved-data-discovery-for-data-scientists-at-spotify/

Lexikon allows employees at Spotify to search and browse available BigQuery tables and discover knowledge generated through past research and analysis. The tool in its present version shows not not the metadata information but also the stewardship, usage, access tier’s, lifecycle information etc. There has been a focus on helping draw insights from the metadata such as to find popular datasets across the company, or to serve personalized dataset recommendations to users. 20% of monthly active users navigate to BigQuery tables through personalized recommendations on the homepage.
Not only this they have also released collaborative tools/plugins on slack to facilitate discussions about datasets, and have seen almost 25% increase in the number of Lexikon links shared on Slack per week.
Databook - Uber
Official Blog: https://eng.uber.com/databook/

Uber’s databook platform manages rich metadata about Uber’s dataset’s and enables employees across the company to discovery data and gather insights. All metadata is accessible via their UI, and also via restful API’s. Databook is powered using a combination of crawlers and which periodically collect information from our various data sources and microservices, and persist in databook’s storage platform. Utilizing an event based architecture, allows databook programmatically trigger other microservices and send communications to data users in near real time.
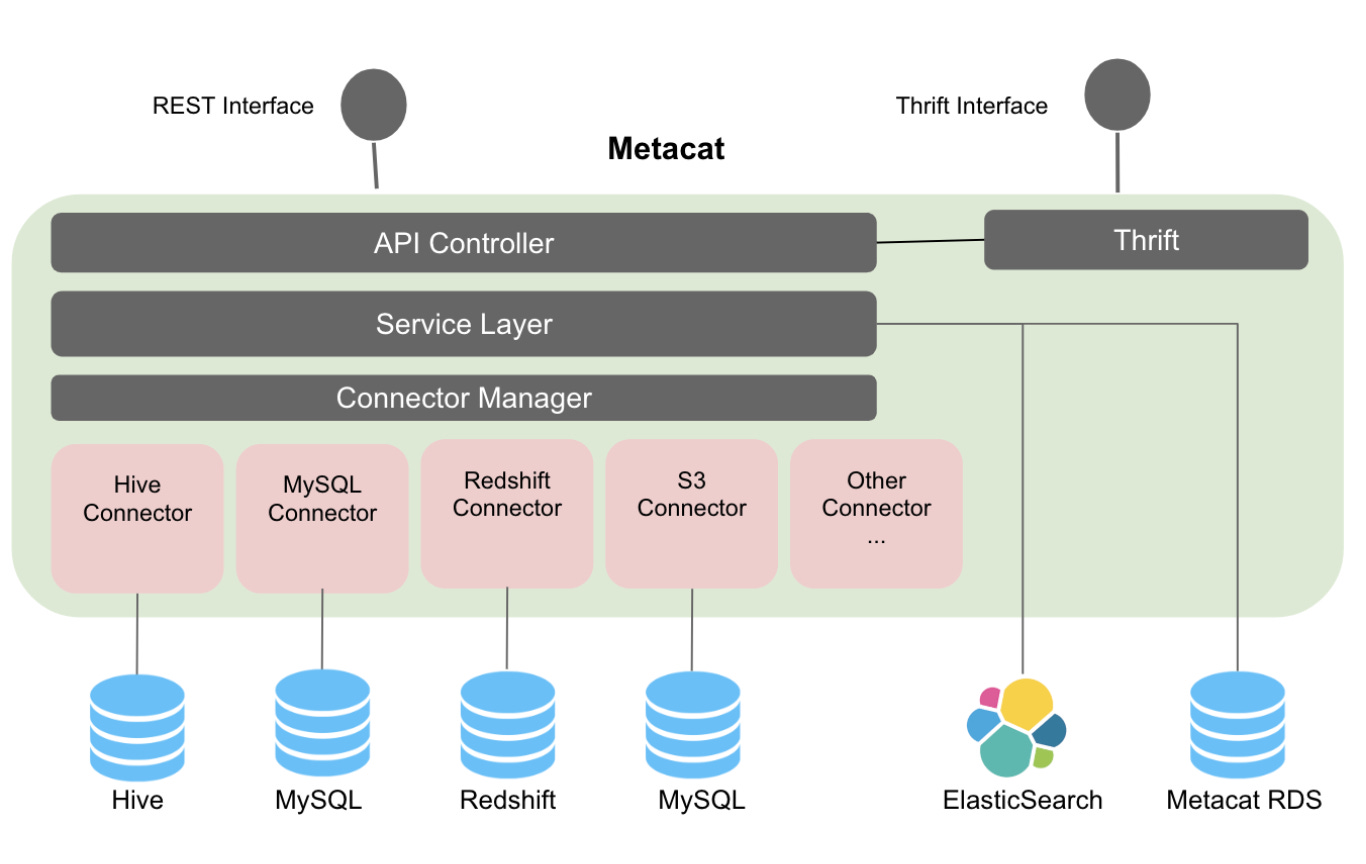
Metacat - Netflix
Official Blog: https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520

( Source )
Metacat is Netflix’s service to access metadata of various datastores. Metacat publishes schema metadata and business/user-defined metadata to Elasticsearch that helps in full-text search for information in the data warehouse. This also enables auto-suggest and auto-complete of SQL in their Big Data Portal SQL editor. Organizing datasets as catalogs helps the consumer browse through the information. Tags are used to categorize data based on organizations and subject areas. In conjunction to Metacat, Netflix utilizes a push based mechanism using its Keystone pipeline to send notification regarding table and partition changes.
Conference Talk:
Note: This blog series is for informational purposes only, and all views are my own and do not represent my employers.
References:
the link for Amundsen post is incorrect. It should be https://eng.lyft.com/open-sourcing-amundsen-a-data-discovery-and-metadata-platform-2282bb436234 .